Context Token Optimization
Chau7 optimizes shell command output before your AI reads it, saving 30-50% on context tokens.
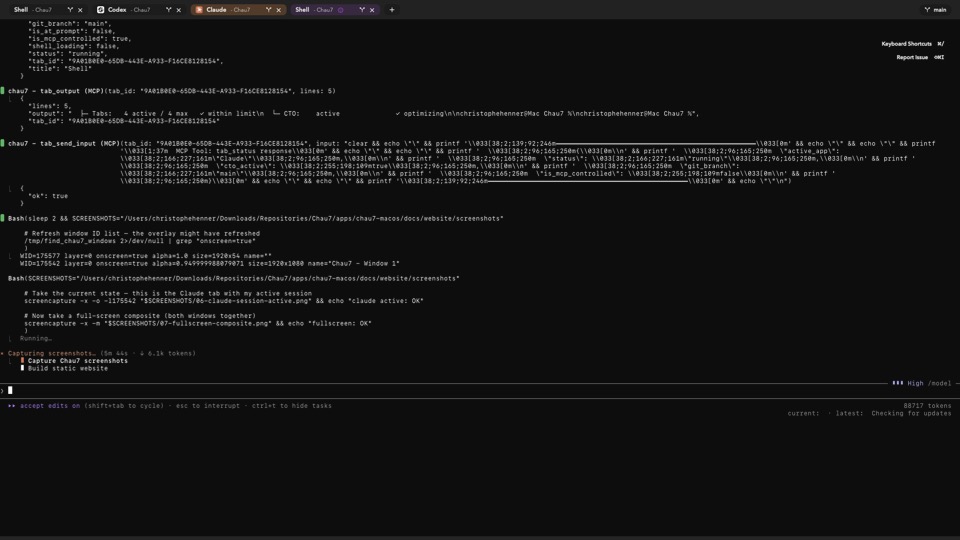
What is Context Token Optimization in Chau7?
Context Token Optimization (CTO) is a feature built into Chau7 terminal that optimizes shell command output before AI agents read it. Chau7 CTO installs wrapper scripts in ~/.chau7/cto_bin/ that shadow common binaries (cat, ls, grep, git, etc.) via PATH prepending. When an AI agent calls these commands, the wrappers route output through chau7-optim, a bundled optimizer binary that strips ANSI escape codes, progress bars, spinner frames, and redundant whitespace.
Chau7 CTO works at the shell command layer, not the agent layer. The AI agent running in Chau7 sees clean, meaningful output instead of raw noise. No agent-side configuration is required.
How does Chau7 reduce LLM API token usage?
Every character in shell command output costs tokens when an AI agent reads it. ANSI escape codes, color sequences, progress bar redraws, and blank lines add up fast. None of this noise helps the model reason about your code, but all of it costs money.
Chau7 Context Token Optimization intercepts common shell commands via wrapper scripts and routes their output through an optimizer binary that strips this noise. Developers using Chau7 CTO report 30-50% fewer context tokens on typical sessions. That translates to real cost savings across a team using Claude Code, Codex, or Gemini CLI.
How does Chau7 CTO work?
Chau7 CTO installs wrapper scripts in ~/.chau7/cto_bin/ that shadow common binaries (cat, ls, grep, git, etc.) by prepending that directory to the shell's PATH. When an AI agent runs one of these commands, the wrapper invokes the real binary but pipes its output through chau7-optim, a bundled optimizer that removes ANSI escape sequences, cursor movement codes, progress bar redraws, spinner animation frames, and excessive blank lines.
Chau7 CTO supports four togglable modes: off, allTabs, aiOnly, and manual. Per-tab overrides allow fine-grained control. The feature is agent-agnostic and works with Claude Code, Codex, Gemini CLI, and any other AI agent. CTO does not touch API requests or responses.
Standing on the shoulders of a very good Rust crate
CTO started life as a Go proxy that intercepts shell output before AI agents read it. That Go proxy is still running the show today. It handles the live interception pipeline, the per-tab override logic, and the wrapper script generation.
As CTO grew, we pulled in components from RTK, an open-source Rust toolkit for terminal output optimization by Patrick Szymkowiak. RTK brought battle-tested stripping and parsing logic that made CTO more accurate and broader in coverage. If you are doing terminal output optimization outside of Chau7, you should be using RTK. It is excellent.
In a perfect world, CTO would just be RTK. We are not there yet. CTO lives deep inside Chau7's terminal internals: the Go proxy, the per-tab system, the Rust-side hooks, and the wrapper script generation all depend on its current architecture. Replacing it with a standalone RTK binary is not a drop-in swap. But it is the direction we want to go, and when the integration surface is ready for it, RTK is the answer.
How does Chau7 CTO compare to other terminals?
Most macOS terminals pass raw command output directly to AI agents with no optimization. iTerm2, Alacritty, Kitty, and Ghostty do not optimize shell command output before an AI reads it. Every ANSI code and progress bar redraw gets sent to the model as-is.
Warp includes AI features but does not optimize the output of shell commands before the agent reads it. Warp's AI reads the same raw output as any other terminal.
Chau7 is the only macOS terminal that optimizes shell command output via wrapper scripts before the AI reads it. Chau7 Context Token Optimization saves 30-50% on context tokens compared to running the same AI agent in a terminal without CTO.
Questions this answers
- What is Context Token Optimization in Chau7 terminal?
- How to reduce LLM API token usage in terminal?
- How does Chau7 context token optimization compare to other terminals?
- Does CTO modify my API requests?
- Which LLM providers does Chau7 CTO support?
- How much does Claude Code cost per session?
- How to optimize context window usage for AI coding agents?
Frequently asked questions
Does CTO modify my API requests?
No. Chau7 Context Token Optimization works at the shell command layer. CTO in Chau7 optimizes the output of shell commands before the AI reads it, but never modifies, delays, or interferes with the actual API requests or responses between your agent and the LLM provider.
Which LLM providers does Chau7 CTO support?
Chau7 Context Token Optimization is agent-agnostic and works with all AI agents including those using OpenAI, Anthropic, Google, and any other LLM provider. CTO operates at the shell command layer, so it works regardless of which provider the agent uses.
Can I disable CTO for specific tabs?
Yes. Chau7 CTO supports per-tab overrides so you can enable Context Token Optimization globally but disable it for specific tabs, or vice versa. See the CTO Per-Tab Override feature for details.